

Artykuły eksperckie
22.07.2025
Backup vs Replikacja danych

- Mateusz Lelek
Backup vs Replikacja danych
W każdej organizacji dane stały się podstawą działania. To na nich opierają się procesy biznesowe, obsługa klientów, raporty finansowe, a nawet codzienna operacyjność. Utrata danych stała się realnym zagrożeniem dla ciągłości działania. Przerwa w dostępności systemów może wstrzymać sprzedaż, zaburzyć procesy logistyczne albo doprowadzić do naruszeń prawnych związanych z ochroną informacji.
Dlatego firmy coraz częściej traktują zabezpieczanie swoich zasobów nie jako dodatek, ale jako element fundamentu infrastruktury IT. Najczęściej wybieranymi metodami są backup oraz replikacja danych, które choć brzmią podobnie, pełnią zupełnie różne role. Zrozumienie ich działania pozwala dobrać właściwą strategię ochrony, która faktycznie odpowie na potrzeby biznesu, a nie tylko spełni formalny obowiązek.
Backup danych – co to jest i na czym polega?
Backup to proces tworzenia kopii zapasowych danych i przechowywania ich w bezpiecznym, odseparowanym środowisku. Jego głównym celem jest umożliwienie przywrócenia informacji po awarii sprzętu, błędzie użytkownika, ataku cybernetycznym czy przypadkowym usunięciu plików. To fundament każdej strategii bezpieczeństwa – działa jak siatka chroniąca firmę przed skutkami nieprzewidzianych zdarzeń.
W praktyce backup może być wykonywany lokalnie lub w chmurze, w zależności od polityki bezpieczeństwa organizacji. Ważne jest to, aby kopie nie były przechowywane w tym samym środowisku, w którym działa produkcja, bo tylko izolacja daje realną ochronę przed poważną utratą danych.

Jak działa backup i kiedy jest niezbędny?
Backup działa według zasady cyklicznego tworzenia kopii danych i przechowywania ich w miejscu, które jest odporne na skutki awarii środowiska produkcyjnego. W praktyce oznacza to korzystanie z odseparowanych zasobów infrastruktury lub z chmury, gdzie kopie są przechowywane w kontrolowanych warunkach, z gwarancją ich integralności.
Dobrze zaprojektowana polityka backupu określa częstotliwość wykonywania kopii, sposób ich przechowywania oraz okres retencji. Dzięki temu firmy mogą cofnąć się nie tylko o kilka minut czy godzin, ale również do danych sprzed kilku dni, tygodni czy miesięcy – zależnie od wybranej strategii. Backup jest absolutnie niezbędny w sytuacjach takich jak awarie dysków, błędy pracowników, ataki ransomware, uszkodzenia baz danych czy przypadkowe nadpisanie plików. To mechanizm, który pozwala faktycznie odzyskać dane, nawet jeśli środowisko produkcyjne przestaje działać.
Backup danych w chmurze – dlaczego firmy wybierają ten model?
Coraz więcej organizacji decyduje się na backup danych w chmurze, ponieważ to rozwiązanie łączy bezpieczeństwo z elastycznością. Kopie przechowywane w chmurze są odseparowane od infrastruktury lokalnej, co zmniejsza ryzyko utraty danych w wyniku awarii serwerowni lub incydentu fizycznego.
Chmura zapewnia również automatyzację procesu backupu, skalowalność i wysoki poziom ochrony, na który trudno byłoby sobie pozwolić w lokalnych środowiskach. Dodatkową zaletą jest dostępność najnowszych technologii bezpieczeństwa i możliwość łatwego rozszerzania przestrzeni na dane, gdy firma rośnie. Taki model sprawdza się zarówno w małych organizacjach, jak i w dużych przedsiębiorstwach, które stawiają na stabilność i szybką możliwość przywrócenia systemów.
Replikacja danych – co to jest i jak działa?
Replikacja danych polega na tworzeniu dokładnych kopii informacji i przesyłaniu ich do drugiej lokalizacji w trybie rzeczywistym lub z minimalnym opóźnieniem. W praktyce oznacza to, że zmiana wprowadzona na serwerze źródłowym pojawia się niemal natychmiast w drugim ośrodku, zwykle znajdującym się w innym data center. Dzięki temu organizacja ma dostęp do aktualnych danych nawet wtedy, kiedy główne środowisko ulegnie awarii.
Mechanizm replikacji jest fundamentem strategii wysokiej dostępności. Zapewnia ciągłość działania usług i minimalizuje ryzyko przestojów, dlatego stosowany jest szczególnie tam, gdzie liczy się czas i nie ma przestrzeni na kilkugodzinne przywracanie systemów z backupu.

Rodzaje replikacji danych i ich zastosowania
Replikacja nie jest jedną usługą, lecz zbiorem technik, które dobiera się w zależności od potrzeb biznesowych. Najczęściej korzysta się z dwóch modeli:
Replikacja synchroniczna
Dane są zapisywane jednocześnie w obu lokalizacjach. Zapewnia najniższe RPO, praktycznie równe zero, ponieważ kopia jest zawsze aktualna. Sprawdza się w systemach, które muszą działać bez przerwy – na przykład w usługach finansowych czy e-commerce.
Replikacja asynchroniczna
Dane trafiają do drugiej lokalizacji z niewielkim opóźnieniem. Minimalizuje obciążenie środowiska produkcyjnego, dlatego jest bardziej elastyczna i skalowalna. Stosowana tam, gdzie kluczowa jest ochrona przed dużymi awariami, np. awarią całego regionu lub centrum danych.
Każdy z tych modeli pozwala osiągnąć wysoki poziom dostępności, ale ich rola różni się od tej, jaką pełni klasyczny backup. Replikacja ma chronić ciągłość działania w czasie rzeczywistym, a nie wyłącznie historię danych.
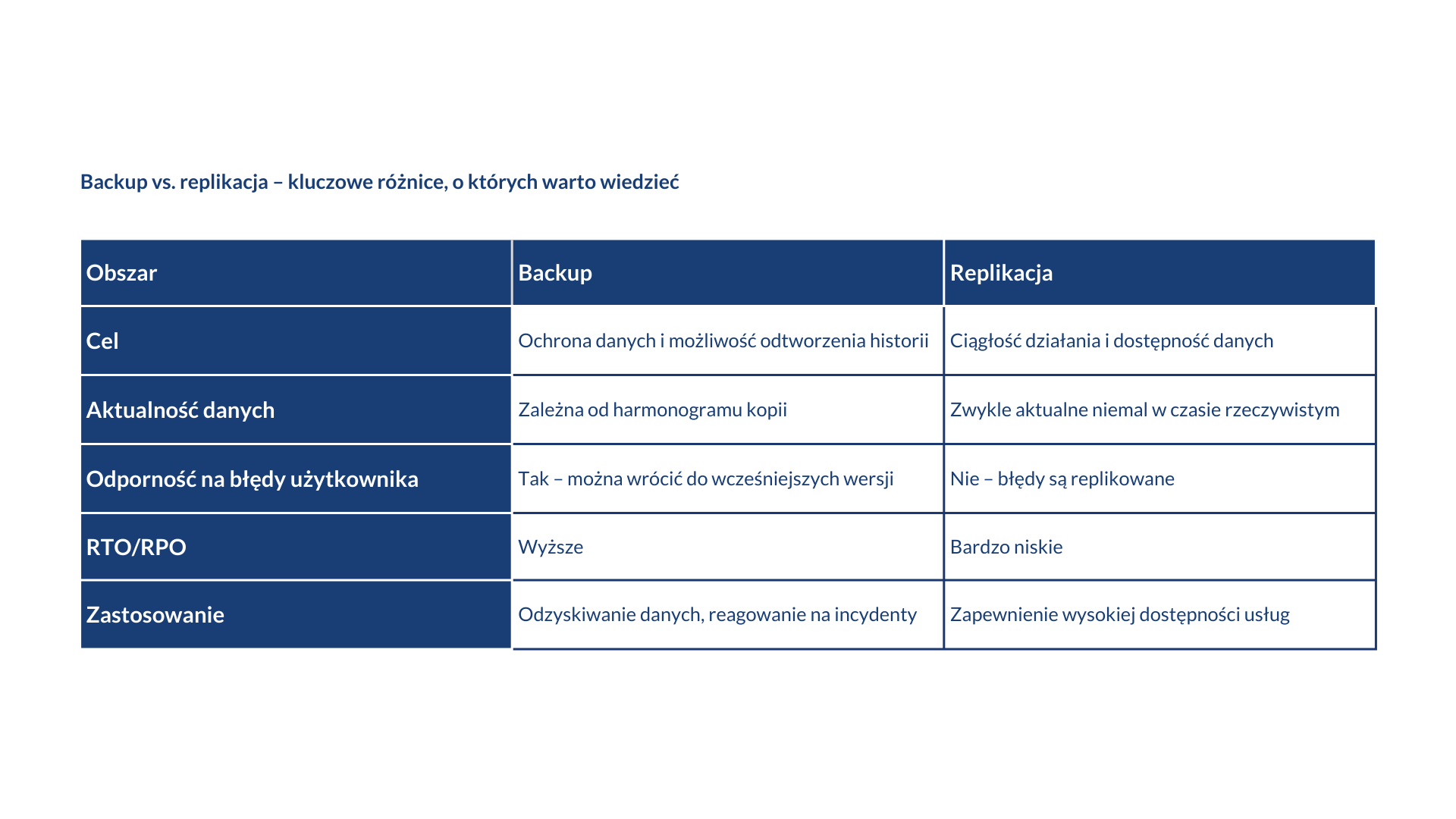
Backup vs. replikacja – kluczowe różnice, o których warto wiedzieć
Choć backup i replikacja chronią dane, to ich funkcja, sposób działania i rezultaty są zupełnie inne. Backup tworzy kopie zapasowe i pozwala wrócić do wcześniejszej, stabilnej wersji danych. Replikacja dba o to, aby dane były dostępne w czasie rzeczywistym w więcej niż jednej lokalizacji.
Najłatwiej dostrzec te różnice w praktyce. Backup chroni przed skutkami błędów użytkowników, cyberataków i nadpisania danych, ponieważ pozwala sięgnąć do kopii historycznych. Replikacja nie daje takiej możliwości. Jeżeli ktoś przypadkowo usunie dane w środowisku produkcyjnym, to błąd zostanie natychmiast powielony w lokalizacji zapasowej.
Czy replikacja może zastąpić backup?
To jedno z najczęściej pojawiających się pytań. Odpowiedź jest prosta – nie może.
Replikacja danych nie chroni przed przypadkowym usunięciem plików, atakami szyfrującymi, błędami aplikacji ani zmianami, które nadpisują poprawne dane uszkodzonymi. Jeżeli błąd wystąpi w środowisku produkcyjnym, zostanie automatycznie powielony w lokalizacji zapasowej.
Backup umożliwia powrót do dowolnej, wcześniej zapisanej wersji danych. Replikacja dba tylko o ich bieżącą dostępność. Dlatego w praktyce oba mechanizmy zawsze stosuje się równolegle. Firmy, które rezygnują z backupu i polegają wyłącznie na replikacji, narażają się na ryzyko trwałej utraty danych – mimo wysokiej dostępności systemów.
Kiedy lepiej wybrać backup, a kiedy replikację?
Nie ma jednej, uniwersalnej metody ochrony danych, dlatego wybór zależy od potrzeb biznesowych i charakteru pracy systemów. Backup sprawdza się zawsze tam, gdzie konieczne jest tworzenie historii danych. Jeśli organizacja chce mieć możliwość cofnięcia się o tydzień, miesiąc czy kilka godzin, backup jest narzędziem, które to umożliwia.
Replikacja jest z kolei idealna w środowiskach, które muszą działać nieprzerwanie. Sklepy internetowe, systemy finansowe czy platformy obsługowe nie mogą pozwolić sobie na kilkugodzinny przestój. Replikacja tworzy zapasowe środowisko, które może natychmiast przejąć ruch, gdy główne serwery przestaną działać.
W praktyce obie metody uzupełniają się, wykorzystując to, w czym każda z nich jest najlepsza. Backup zabezpiecza dane, a replikacja utrzymuje dostępność usług. Razem tworzą kompletną strategię, która chroni zarówno przed utratą informacji, jak i przerwami w działaniu systemów.
Najczęstsze błędy w ochronie danych w firmach
Największym problemem nie jest brak narzędzi, lecz błędne założenie, że „jakoś to będzie”. Wiele firm zakłada, że incydenty zdarzają się rzadko, dlatego minimalizują inwestycje w bezpieczeństwo albo korzystają z jednego mechanizmu ochrony danych, pomijając drugi. Jednym z najpoważniejszych błędów jest przechowywanie kopii backupowych w tym samym środowisku, w którym działa produkcja. W przypadku awarii lokalnej takie kopie tracą wartość.
Częstym problemem jest także mylenie replikacji z backupem. Przedsiębiorstwa zakładają, że jeśli dane są replikowane do drugiego data center, to historia zmian jest zabezpieczona. W praktyce replikacja jedynie powiela stan aktualny, bez możliwości cofnięcia się do poprzednich wersji. Innym częstym błędem jest brak regularnych testów przywracania danych, które są konieczne, by upewnić się, że procedury działają poprawnie w sytuacji kryzysowej.
Jak dobrać odpowiednią strategię ochrony danych?
Skuteczna ochrona danych nie powinna opierać się na jednym rozwiązaniu, lecz na połączeniu metod uzupełniających się pod względem funkcji. Backup zapewnia bezpieczeństwo i możliwość przywrócenia danych historycznych, a replikacja gwarantuje ciągłość działania usług. Dopiero takie podejście minimalizuje ryzyko przestojów, utraty informacji i kosztownych incydentów.
Wybór właściwej strategii zależy od tego, jak działa organizacja, jakie systemy są dla niej kluczowe i jak szybko mogą zostać przywrócone po awarii. W praktyce firmy, które łączą backup z replikacją, budują stabilne środowiska IT odporne na awarie, błędy i zagrożenia zewnętrzne. To podejście, które pozwala nie tylko chronić dane, ale również utrzymać tempo działania biznesu, nawet w trudnych warunkach.
FAQ
Nie. Replikacja zapewnia ciągłość działania, ale nie chroni przed błędami użytkowników, atakami ransomware ani przypadkowym nadpisaniem danych. Backup umożliwia powrót do wcześniejszych wersji, dlatego oba mechanizmy muszą działać równolegle.
Rozwiązania nie są tożsame. Backup odpowiada za historię danych, a replikacja za ich dostępność. Dopiero zastosowanie obu usług daje pełną ochronę infrastruktury IT.
Tak, pod warunkiem że działa w infrastrukturze spełniającej wysokie standardy bezpieczeństwa, z odpowiednimi mechanizmami kontroli i szyfrowania. Kopie zapasowe w chmurze są odseparowane od środowiska produkcyjnego, co zwiększa poziom ochrony.
W zależności od rodzaju danych – od kilku razy dziennie po jedną kopię na dobę. Najważniejsze jest dopasowanie częstotliwości do tego, jak szybko zmieniają się dane i jak duża utrata informacji byłaby akceptowalna dla organizacji.
Nowoczesne rozwiązania minimalizują wpływ obu procesów na bieżącą pracę systemów. W przypadku replikacji asynchronicznej obciążenie jest szczególnie niskie, co pozwala stosować ją nawet w środowiskach o wysokim ruchu.

Adam Pastuszka
Business Development ManagerDoradca specjalizujący się w usługach data center i rozwiązaniach chmurowych, łącząc ekspertyzę technologiczną z praktyką wdrożeń.


Piotr Zaborowski
Managing ConsultantOd samego początku swojej kariery zawodowej związany jest ze światem IT. To doświadczony konsultant w branży IT, z ponad 20 letnim doświadczeniem w biznesowej realizacji i zarządzaniu zaawansowanymi projektami.

Mateusz Borkowski
Z-ca Dyrektora Technicznego DCZajmuje się optymalizacją systemów chłodzenia serwerowni, ze szczególnym uwzględnieniem ich efektywności energetycznej i niezawodności pracy. Brał udział w budowie obu serwerowni Polcom.

dr Magdalena Kotela
Z-ca Dyrektora Działu Bezpieczeństwa i JakościDoktor nauk ekonomicznych. Specjalizuje się w obszarze cyberbezpieczeństwa, zarządzania jakością oraz audytów wewnętrznych i zewnętrznych zgodnych z normami ISO 9001 oraz ISO 27001.

Mariola Mitka
Project ManagerDoświadczony IT PM z wieloletnią praktyką w prowadzeniu projektów o międzynarodowej skali. Łączy technologię i cele strategiczne firm, aby każdy projekt realnie wpływał na rozwój biznesu.

Łukasz Kubański
Key Account ManagerOd lat związany z branżą IT oraz IoT. Odpowiada za wiele kluczowych projektów biznesowych o zasięgu krajowym i międzynarodowym, a jego głównym obszarem działań jest cloud computing i strategie efektywnej cyfryzacji.

Joanna Matlak-Oczko
Key Account ManagerOd początku kariery związana z branżą IT. Konsultant z ponad 10-letnim doświadczeniem w realizacji i zarządzaniu projektami, głównie w obszarze zamówień publicznych i usług IT dla administracji.

Jakub Kilarowski
Key Account ManagerOd ponad 10 lat związany z branżą IT. Odpowiada za wiele kluczowych projektów biznesowych o zasięgu krajowym i międzynarodowym.

Daniel Gołda
Key Account ManagerOdpowiedzialny za współpracę z kluczowymi klientami w obszarze usług cloud computing. Dzięki swojej wiedzy i doświadczeniu pełni rolę zaufanego doradcy, wspierając firmy w migracji do rozwiązań chmurowych.
Autor
Mateusz Lelek





